

ガーベージイン・ガーベージアウト ― これは常にコンピューティングのルールであり、機械学習も例外ではない。基本的にAIは、教えられたことしか知らないので、データに何らかの偏見があれば、それに基づいて訓練されたシステムもそうなる。
Googleは、そんな厄介で深刻な問題を引き起こしかねない状態を、”Equality of Opportunity” [機会均等]と名付けた方法を用いて系統的に回避しようとしている。
機械学習システムは、基本的に様々なデータ集合の性質学習する予測エンジンから成り、新たなデータを与えられるといくつかあるバケツのどれかに分類する。
画像認識システムなら、車のタイプの違いを学習し、それそれの写真に「セダン」「ピックアップトラック」「バス」等のラベル付ける。
間違いは避けられない。スバルのBRATやシボレーのEl Caminoを考えてみてほしい。コンピューターがどう判断するにせよ、それは間違っている。この少数しか存在しない車両タイプのデータを十分に持っていないからだ。
この例の誤りから起きる問題は取るに足らないだろうが、もしコンピューターが車でなく人間を調べ、住宅ローン不払いのリスクによって分類したらどうだろうか?
共通パラメーターから外れた人々は、システムがデータに基づいて良好と考える条件に当てはまらない可能性が高くなる ― それが機械学習のしくみだからだ。
グループのメンバー情報に、繊細な属性、例えば人種、性別、障害、宗教等があった場合、不公平あるいは偏見をともなう結果を招きかねない」とGoogle BrainのMoritz Hardtがブログに書いている。
「ニーズがあるにもかかわらず、繊細な属性に基づくこの種の差別を防ぐための十分吟味された方法論が、機械学習には存在しない」
Hardtは、同僚のEric Price、Nathan Srebroと共同で、この種の結果を避ける方法を説明した論文をまとめ、この種の結果を避ける方法を記載した。次のような数式がたくさん書かれている。
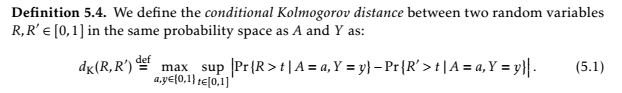{kind=link}

Kolmo-what now?
しかし要点はこうだ:望ましい結果が存在し、誤った属性のために正しい結果を得られない可能性があるとき、アルゴリズムが自らを調整して、その属性によらず結果の分布が均等になるようにする ― 即ち、本質的でない属性間に等しい価値を置くようシステムを訓練する。
チームが作ったこのインタラクティブ・チャートを使うと直感的に理解できるだろう。これは道徳的に正しい数字をひねり出すためのものではない。モデルの結果はむしろ予測を正確に反映している。
もし、ある属性に意味があるなら ― 地域に基づいて信仰する宗教を計算したり、性別による医学的予測を行う場合等 ― それを判定基準に含めればよい。
機械学習が多くの業界で急速に広まる中、Googleの取り組みは実に思慮深く、極めて意義が大きい。新たなテクノロジーの限界とリスクをよく理解しておくことは大切であり、これは地味だが重要な活動だ。
著者らはNeural Information Processing Systems会議で論文を発表する — 誰もがバルセロナを訪れる良い理由だ。
[原文へ]
(翻訳:Nob Takahashi / facebook)
(2016年10月10日 TechCrunch日本版「Google、AIから偏見を排除する方法を研究中」より転載)
【関連記事】